Metódy komprimujúce pomocou slovníka
Tieto kompresné metódy využívajú toho, že v komprimovaných dátach sa nachádzajú opakujúce sa sekvencie dát. Všetky slovníkové metódy môžeme rozdeliť do dvoch základných skupím.
Metódy z prvej skupiny sa pokúšajú nájsť, či práve komprimovaná sekvencia znakov sa už skôr nevyskytovala vo vstupnom prúde dát a namiesto jej opakovania, zapíšeme na výstup odkaz na jej predchádzajúci výskyt v prúde dát. Princíp je zobrazený na obrázku.
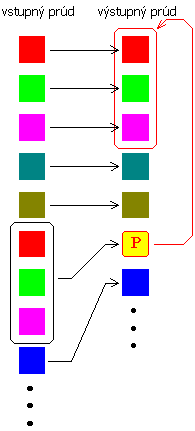
Všetky algoritmy z tejto skupiny sú založené na algoritme publikovanom v roku 1977 pánmi Abrahamom Lempelom a Jakobom Zivom s názvom LZ77. Ďalšie modifikácie tochto algoritmu nesú názvy LZSS, LZB, LZH,...
Druhá skupina algoritmov si vytvára slovník reťazcov, ktoré sa vyskytli vo vstupnom prúde dát. Pokiaľ kompresor narazí na reťazec, ktorý už bol umiestnený v slovníku (resp. vyskytoval sa v predchádzajúcom prúde dát), zapíše na výstup kód, ktorý reprezentuje reťazec uložený v slovníku. Najlepšie princíp tejto metódy ilustruje obrázok.
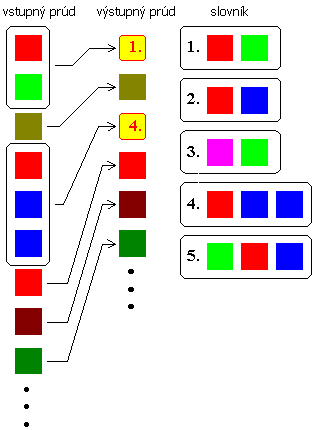
Metódy z tejto skupiny majú základy v algoritme, ktorý v roku 1978 publikovali Lempel a Ziv a je označovaný ako LZ78. V roku 1984 modifikoval metódu LZ78 pán Terry Welch a nesie označenie LZW.
Obrázky sú prevzaté z http://www.rasip.fer.hr/research/compress/index.html